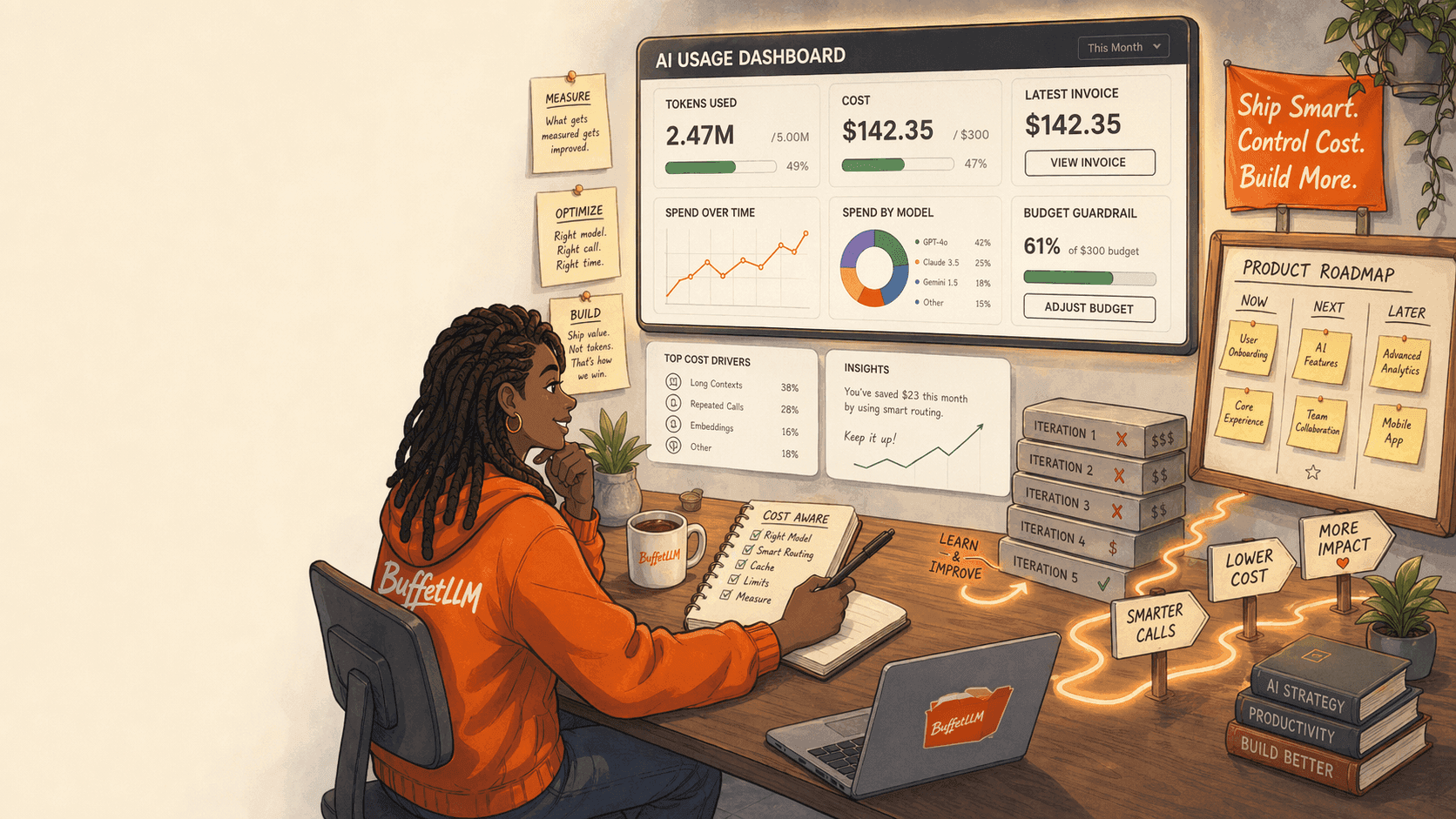
When a team starts using AI, it almost always miscalculates the cost. Not because the data is unavailable, but because most teams only look at token pricing or the monthly subscription and ignore everything else: iterations, long prompts, failed tests, model switching, rework, and how people actually use the tools over a full month.
The result is predictable: at first it looks cheap, then usage grows without control, and eventually someone concludes that AI does not pay off as much as expected.
Most of the time, the problem is not AI. The problem is that nobody did the math correctly.
The mistake: confusing price with real cost
The visible price of using a model is only one part of the picture.
Real cost includes:
- How many times you repeat a task
- How much context you send on each prompt
- How many team members use it
- How many attempts it takes to get something useful
- How much manual cleanup still remains
If you do not include that in the equation, you are estimating blindly.
The simple formula
To get a quick estimate, use this structure:
`monthly cost = users x tasks per day x attempts per task x average cost per attempt x active days`
It does not need to be perfect. It needs to be honest.
A very realistic example
Imagine a small team of 3 people using AI for:
- Copywriting
- Coding
- Document analysis
- Internal Q&A
Assume:
- 3 users
- 12 tasks per day per person
- 2.5 attempts per task on average
- 22 working days per month
That gives you:
`3 x 12 x 2.5 x 22 = 1,980 attempts per month`
Now imagine each attempt carries a small average cost when you combine input and output. Even with low unit costs, the total stops being trivial very quickly. And that is before you count long contexts, errors, or tasks that repeat because the wrong model was chosen.
What actually drives cost up
There are 4 things that usually inflate the bill much more than expected.
1.Using expensive models for cheap tasks
You do not need the same level of power to:
- Generate ideas
- Rewrite a paragraph
- Classify tickets
- Review one line of copy
If everything runs through the same premium model, cost rises without adding real value.
2.Too much repetition
AI does not just cost money per call. It costs money when the task itself is poorly defined.
When the prompt is vague or the workflow is unclear, every mediocre output leads to another attempt. That is where budget starts leaking.
3.Long context without control
Sending entire conversations, full documents, or huge blocks of context on every call is convenient, but expensive.
In many cases, the model does not need all of that to do the job.
4.Fragmented tools and subscriptions
Multiple accounts, multiple limits, multiple platforms, and multiple workflows create a quieter but very real cost:
- Lost time
- Less effective model comparison
- Duplicate usage
- Poorer governance
How to estimate without overcomplicating it
You do not need a giant spreadsheet. It is enough to split your usage into 3 levels:
Level 1: light usage
- Occasional testing
- Few people
- Isolated tasks
Here the risk is not cost. The risk is pretending this represents future usage.
Level 2: continuous usage
- AI integrated into daily tasks
- Multiple team members
- Frequent iteration
At this stage, you need to control which model gets used for which job.
Level 3: operational usage
- Internal workflows
- Recurrent processing
- Chained tasks
- Automations or high-volume jobs
Here, every small inefficiency multiplies.
What you should measure every month
If you want to keep spending under control, review these 5 metrics:
- Cost per active user
- Cost per completed task
- Average number of attempts per task
- Percentage of tasks that require manual rework
- Usage split by model type
That is already enough to tell whether your problem is the model, the prompt, or the process.
Cutting cost does not always mean using the cheapest model
This matters a lot.
If a cheaper model requires 4 attempts where another one solves the task in 1, the cheaper model is not saving money. It is hiding cost.
The goal is not to pay less per call. The goal is to pay less per useful outcome.
A healthier way to think about cost
A reasonable strategy usually looks like this:
- Lower-cost models for exploration and repetitive work
- Stronger models for decisions, analysis, and final deliverables
- Clear internal rules so the team is not improvising every time
Without that, cost grows because of disorder, not because of scale.
Where BuffetLLM fits
BuffetLLM is built around exactly this tension: builders want to test more, compare more, and ship better work, but the current setup punishes iteration with limits, fragmented billing, and too much friction.
If access to strong models is expensive or awkward, teams experiment less. And when they experiment less, roadmaps become slower and more conservative.
Closing thought
Calculating the real cost of AI is not just a finance exercise. It is a product and operations decision.
If you know what a useful task actually costs, you can optimize it. If you only look at the surface-level price of a tool, you are already behind.



